UnixBenchでLinuxサーバのCPU性能を比較する

UnixBenchを使うことで、Linux/Unix系サーバのベンチマークを取得することが可能になります。測定できる主な性能はCPUです。
クラウドの登場により、サーバスペックを簡単に変更できるようになりました。ハードウェアレイヤが仮想化されているため、CPUはvCPUと表記されることが多く、クロック数等の明記がないことも多々見受けられます。
IaaSベンダーによっては、明確なクロック数の表記がなく、こっちのほうが高スペックです!と提示されているケースもあります。
CPUスペックの違いを可視化するために、UnixBenchを利用してみます。
Contents
- 1 UnixBenchとは
- 2 UnixBenchの使い方
- 2.1 UnixBenchのインストール方法
- 2.2 UnixBenchの実行方法
- 2.3 測定可能なテストケース
- 2.3.1 Dhrystone 2 using register variables
- 2.3.2 Double-Precision Whetstone
- 2.3.3 Execl Throughput
- 2.3.4 File Copy 1024 bufsize 2000 maxblocks
- 2.3.5 File Copy 256 bufsize 500 maxblocks
- 2.3.6 File Copy 4096 bufsize 8000 maxblocks
- 2.3.7 Pipe Throughput
- 2.3.8 Pipe-based Context Switching
- 2.3.9 Process Creation
- 2.3.10 Shell Scripts (1 concurrent)
- 2.3.11 Shell Scripts (8 concurrent)
- 2.3.12 System Call Overhead
- 3 UnixBenchの結果の見方
- 4 AWSとNIFTY Cloudのベンチマーク結果
- 5 まとめ
UnixBenchとは
UnixBenchとは、Linux/Unix系OSで使われている定番のベンチマークツールです。主にCPUのベンチマークを取るのに使います。
結果の数値は、1990年前後にあった、GeorgeというUNIXシステムの性能を基本として数値化しています。基本的な数値が10なので、結果が1,000であればGeorgeより100倍高速ということができます。
UnixBenchの使い方
CentOS6環境でのUnixBenchの使い方を説明します。
UnixBenchのインストール方法
必要なモジュールをインストールします。
yum install gcc yum install perl-Time-HiRes
モジュールの準備が整ったら、UnixBenchをダウンロードし、解凍します。
cd /usr/local/src wget https://byte-unixbench.googlecode.com/files/UnixBench5.1.3.tgz tar xvzf UnixBench5.1.3.tgz
※ダウンロードURLが変更されているようです。
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/byte-unixbench/UnixBench5.1.3.tgz
これでUnixBenchを実行する環境が整いました。
UnixBenchの実行方法
実行は、解凍したフォルダへ移動し、Runを実行します。実行時間が結構ながいので、30分ほど気長に待ちましょう。
cd UnixBench ./Run
30分も待てないよ!という方は、各種オプションを利用して時間短縮をしてみましょう。必要に応じて指定すると、効率的にベンチマークを取ることが可能です。
Run [ -q | -v ] [-i] [-c [-c ...]] [test ...]
各種オプションは次の通りです。
| オプション | 内容 |
|---|---|
| -q | 不要な出力を抑止します。 |
| -v | 実行コマンドなどの詳細情報を出力します。 |
| -i <n> | <n>に繰り返し回数を指定します。指定が無い場合は、10回繰り返されます。 |
| -c <n> | <n>に計測時のCPUの数を指定します。指定が無い場合は、1コアの場合と、全てのコアの場合が実行されます。 |
| test | 実行するテストケースを指定します。 |
詳細情報を出力しながら、execlのテストを5回繰り返したい場合は次のように指定します。
./Run -v -i 5 execl
測定可能なテストケース
標準で実行されるテストケースは次の通りです。個別に実行したい場合は、カッコの中のテスト名を指定します。
Dhrystone 2 using register variables
テストケース : dhry2reg
整数演算処理の性能をベンチマークします。Dhrystoneというベンチマークツールを利用しています。
Double-Precision Whetstone
テストケース : whetstone-double
浮動小数演算処理の性能をベンチマークします。Whetstoneというベンチマークツールを利用しています。
Execl Throughput
テストケース : execl
システムコール処理性能をベンチマークします。execl()というプロセスイメージを置き換えるシステムコールを繰り返します。
File Copy 1024 bufsize 2000 maxblocks
テストケース : fstime
元々はディスクの処理性能を測るものでしたが、メモリやCPUのキャッシュ増大により、ディスク処理性能ではなくOSとCPUの処理性能をみるものになっています。ファイルのコピーを繰り返すテストで、2MByteのファイルを1024Byteごとに処理します。
File Copy 256 bufsize 500 maxblocks
テストケース : fsbuffer
fstimeと同様のテスト内容で、500KByteのファイルを256Byteごとに処理します。
File Copy 4096 bufsize 8000 maxblocks
テストケース : fsdisk
fstimeと同様のテスト内容で、8MByteのファイルを4096Byteごとに処理します。
Pipe Throughput
テストケース : pipe
元々はメモリの処理性能を図るものでしたが、CPUのキャッシュ増大により、メモリ処理性能ではなく、OSとCPUの処理性能を見るためのものになっています。512Byteのデータのパイプ処理を繰り返しスループットをテストします。
Pipe-based Context Switching
テストケース : context1
OSとCPUの処理性能をみます。2つのプロセス間で更新される値をパイプで渡すことで、プロセスのコンテキストスイッチを実行させます。
Process Creation
テストケース : spawn
OSとCPUの処理性能をみます。プロセスのフォークを繰り返します。
Shell Scripts (1 concurrent)
テストケース : shell1
CPUの処理性能をみます。sort、grepなどテキスト処理を繰り返します。
Shell Scripts (8 concurrent)
テストケース : shell8
shell1と同じ処理を、8個並列に実施します。
System Call Overhead
テストケース : syscall
OSとCPUの処理性能をみます。getpid()というシステムコールを繰り返し実行します。
UnixBenchの結果の見方
次のような実行結果が表示されます。
======================================================================== BYTE UNIX Benchmarks (Version 5.1.3) System: localhost.localdomain: GNU/Linux OS: GNU/Linux -- 2.6.32-358.el6.x86_64 -- #1 SMP Fri Feb 22 00:31:26 UTC 2013 Machine: x86_64 (x86_64) Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8") CPU 0: Intel(R) Xeon(R) CPU E5-2690 v2 @ 3.00GHz (6000.0 bogomips) x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET CPU 1: Intel(R) Xeon(R) CPU E5-2690 v2 @ 3.00GHz (6000.0 bogomips) x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET 15:41:47 up 13 min, 1 user, load average: 0.00, 0.00, 0.00; runlevel 3 ------------------------------------------------------------------------ Benchmark Run: 木 10月 30 2014 15:41:47 - 16:09:51 2 CPUs in system; running 1 parallel copy of tests Dhrystone 2 using register variables 37229876.9 lps (10.0 s, 7 samples) Double-Precision Whetstone 4000.4 MWIPS (9.9 s, 7 samples) Execl Throughput 4545.9 lps (30.0 s, 2 samples) File Copy 1024 bufsize 2000 maxblocks 1150993.4 KBps (30.0 s, 2 samples) File Copy 256 bufsize 500 maxblocks 319485.0 KBps (30.0 s, 2 samples) File Copy 4096 bufsize 8000 maxblocks 3288203.3 KBps (30.0 s, 2 samples) Pipe Throughput 2156689.3 lps (10.0 s, 7 samples) Pipe-based Context Switching 402949.4 lps (10.0 s, 7 samples) Process Creation 12315.8 lps (30.0 s, 2 samples) Shell Scripts (1 concurrent) 7222.7 lpm (60.0 s, 2 samples) Shell Scripts (8 concurrent) 1619.1 lpm (60.0 s, 2 samples) System Call Overhead 2618668.7 lps (10.0 s, 7 samples) System Benchmarks Index Values BASELINE RESULT INDEX Dhrystone 2 using register variables 116700 37229876.9 3190.2 Double-Precision Whetstone 55 4000.4 727.3 Execl Throughput 43 4545.9 1057.2 File Copy 1024 bufsize 2000 maxblocks 3960 1150993.4 2906.5 File Copy 256 bufsize 500 maxblocks 1655 319485 1930.4 File Copy 4096 bufsize 8000 maxblocks 5800 3288203.3 5669.3 Pipe Throughput 12440 2156689.3 1733.7 Pipe-based Context Switching 4000 402949.4 1007.4 Process Creation 126 12315.8 977.4 Shell Scripts (1 concurrent) 42.4 7222.7 1703.5 Shell Scripts (8 concurrent) 6 1619.1 2698.6 System Call Overhead 15000 2618668.7 1745.8 ======== System Benchmarks Index Score 1788.2 ------------------------------------------------------------------------ Benchmark Run: 木 10月 30 2014 16:09:51 - 16:37:55 2 CPUs in system; running 2 parallel copies of tests Dhrystone 2 using register variables 74460260.1 lps (10.0 s, 7 samples) Double-Precision Whetstone 7998.5 MWIPS (9.9 s, 7 samples) Execl Throughput 10344.6 lps (30.0 s, 2 samples) File Copy 1024 bufsize 2000 maxblocks 1472854.9 KBps (30.0 s, 2 samples) File Copy 256 bufsize 500 maxblocks 395038.8 KBps (30.0 s, 2 samples) File Copy 4096 bufsize 8000 maxblocks 4741362.5 KBps (30.0 s, 2 samples) Pipe Throughput 4307783.4 lps (10.0 s, 7 samples) Pipe-based Context Switching 813515.8 lps (10.0 s, 7 samples) Process Creation 28973.8 lps (30.0 s, 2 samples) Shell Scripts (1 concurrent) 12119.5 lpm (60.0 s, 2 samples) Shell Scripts (8 concurrent) 1557.0 lpm (60.0 s, 2 samples) System Call Overhead 4200485.6 lps (10.0 s, 7 samples) System Benchmarks Index Values BASELINE RESULT INDEX Dhrystone 2 using register variables 116700 74460260.1 6380.5 Double-Precision Whetstone 55 7998.5 1454.3 Execl Throughput 43 10344.6 2405.7 File Copy 1024 bufsize 2000 maxblocks 3960 1472854.9 3719.3 File Copy 256 bufsize 500 maxblocks 1655 395038.8 2386.9 File Copy 4096 bufsize 8000 maxblocks 5800 4741362.5 8174.8 Pipe Throughput 12440 4307783.4 3462.8 Pipe-based Context Switching 4000 813515.8 2033.8 Process Creation 126 28973.8 2299.5 Shell Scripts (1 concurrent) 42.4 12119.5 2858.4 Shell Scripts (8 concurrent) 6 1557 2595 System Call Overhead 15000 4200485.6 2800.3 ======== System Benchmarks Index Score 3006.3
マルチコアの場合は、2つの実行結果が表示される
マルチコアの場合は、2つの実行結果が表示されます。1コアの場合と全てのコアの場合です。
1コアのベンチマーク結果のヘッダ
2 CPUs in system; running 1 parallel copy of tests
全てのコア(2コア)のベンチマーク結果のヘッダ
2 CPUs in system; running 2 parallel copy of tests
コア数をどのように変更して測定しているのか?
「1コアの場合と全コアの場合の測定はどのようにおこなっているのか?」気になって調べてみました。どうやら、ベンチマークするためのシェルをコア数だけ並列稼働させることで測定しているようです。
実際に確認してみたい人は、ターミナルを2つ立ち上げます。1つのターミナルでは、プロセス状況をモニタリングし(ターミナルA)、もうひとつのターミナルで実行(ターミナルB)します。
ターミナルB
./Run -i 1 pipe
ターミナルA
watch -n 5 "ps auwxxx|grep UnixBench" Every 5.0s: ps auwxxx|grep UnixBench Fri Oct 31 18:02:24 2014 root 2218 0.0 0.2 106056 1288 pts/0 S+ 18:02 0:00 sh -c "/usr/local/src/UnixBench/pgms/pipe" 10 2>&1 >> "/usr/local/src root 2219 91.2 0.0 3920 384 pts/0 R+ 18:02 0:03 /usr/local/src/UnixBench/pgms/pipe 10 root 2223 0.0 0.2 107672 1460 pts/1 S+ 18:02 0:00 watch -n 5 ps auwxxx|grep UnixBench? root 2224 0.0 0.2 106056 1276 pts/1 S+ 18:02 0:00 sh -c ps auwxxx|grep UnixBench? root 2226 0.0 0.1 107452 936 pts/1 S+ 18:02 0:00 grep UnixBench
ターミナルAで、/usr/local/src/UnixBench/pgms/pipe を実行している様子が分かると思います。
System Benchmarks Index Scoreの値を確認する
まず確認すべきは最下段の「System Benchmarks Index Score」です。全テストケースの総合点となるので、単純にこの数字を比較することになります。
各テストケースごとに比較したい場合は、各テストケースのINDEXの数値を比較します。
結果を比較する
一つのベンチマーク結果だけでは意味が無いので、基本となる環境でのベンチマーク結果と比較します。
結果をExcelなどで表にして比較すると良いと思います。
AWSとNIFTY Cloudのベンチマーク結果
参考までに、AmazonWebServices(AWS)の「c3.large」と、NIFTY Cloud(ニフティクラウド)の「e-medium」および「medium」のベンチマーク結果を掲載しておきます。全てのサーバタイプのvCPUは、2vCPUで、CentOS6(AWSはAmazonLinux)の初期インストール状態です。実行コマンドは、オプション指定なしです。
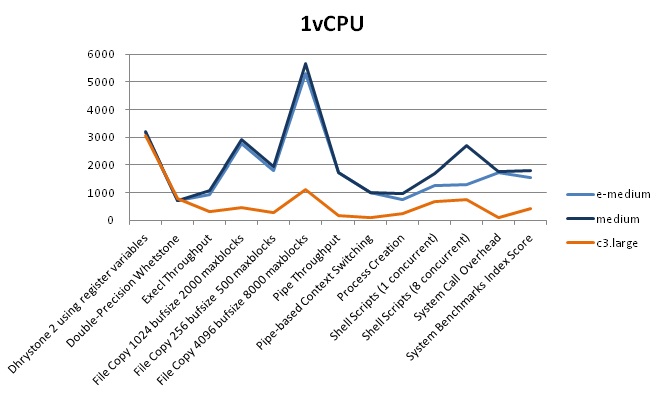
1vCPUの測定結果
| サーバ | 結果数値 |
|---|---|
| AWS/c3.large | 414 |
| NIFTY Cloud/e-medium | 1,554 |
| NIFTY Cloud/medium | 1,788 |
2vCPUの測定結果
| サーバ | 結果数値 |
|---|---|
| AWS/c3.large | 585 |
| NIFTY Cloud/e-medium | 1,534 |
| NIFTY Cloud/medium | 3,006 |
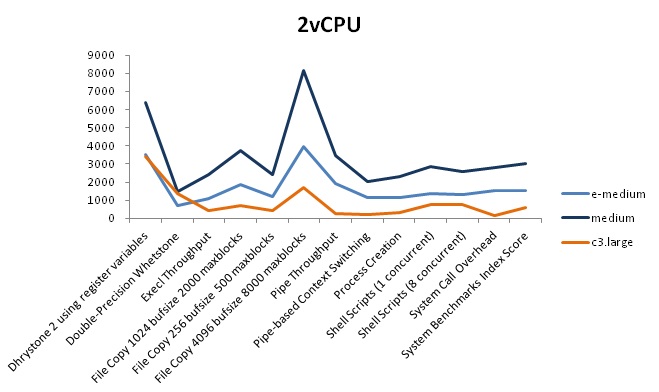
AWSとNIFTY Cloudを比較すると、NIFTY Cloudのほうが4倍程度INDEXスコアが良い結果となりました。
1vCPU、2vCPUのINDEXスコアを見てみると、mediumの場合は、vCPUの分だけスコアが上がっています。
c3.largeとe-mediumはvCPUによって、それほどかわらないスコアになっています。理由はわかりませんが、クロック数とコア数、2つの関係で制限を掛けていたりするのでしょうか?(2コア利用できて、合計周波数が3.0GHzまで等)ご存じの方がいれば教えてください!
まとめ
UnixBenchを利用することで、相対的にCPU性能を可視化することができました。
UnixBenchの特徴をまとめると次のようになります。
- プラットフォームはLinux
- オープンソース(OSS)である
- 主にCPUのベンチマークが可能
- 結果は、相対的に比較しなければ意味が無い
カタログスペックを鵜呑みにせずに、自分でも実際に確認できるといいですね。


この記事へのコメントはこちら